Taking a look at Triton
Over the past year, I’ve been learning CUDA to squeeze out more performance from GPUs and to get a better idea of how GPUs work. Indeed, it’s been a great learning challenge! Unfortunately, there are many more things to consider when writing CUDA kernels than just thinking about the algorithm you are trying to implement. For example, how you are going to structure your grids and blocks, or if you are going to use shared memory or not. I don’t regret learning more about CUDA, but oh boy do I wish I would have taken the leap to learn Triton sooner!
Triton - as advertised by OpenAI - is a new GPU programming language that is a lot simpler to work with than CUDA and gives you pretty amazing performance without much fine-tuning. In comparison, there is a lot of fine-tuning required when trying to squeeze out more performance from CUDA kernels. For example, if you write your own matrix multiplication kernels, they will likely be 10-20x slower than proprietary highly-optimized matrix multiplication kernels - even when using shared memory. Believe me, I’ve tried. Look at Simon Boehm’s amazing blog post for a deep dive into the iterative process of optimizing CUDA kernels for matrix multiplication to get a better idea. In comparison, the third tutorial on Triton’s tutorial page shows you how to write a matrix multiplication kernel that is on par with torch.matmul without many crazy optimizations!
Learning Triton
Triton does not have as many tutorials and examples as you would find for CUDA. I would recommend taking a look at Sasha Rush’s puzzle series, a YouTube tutorial I found on the GPU mode series by Umer Adil which I found valuable; and the tutorials provided on Triton’s website.
My first Triton kernel
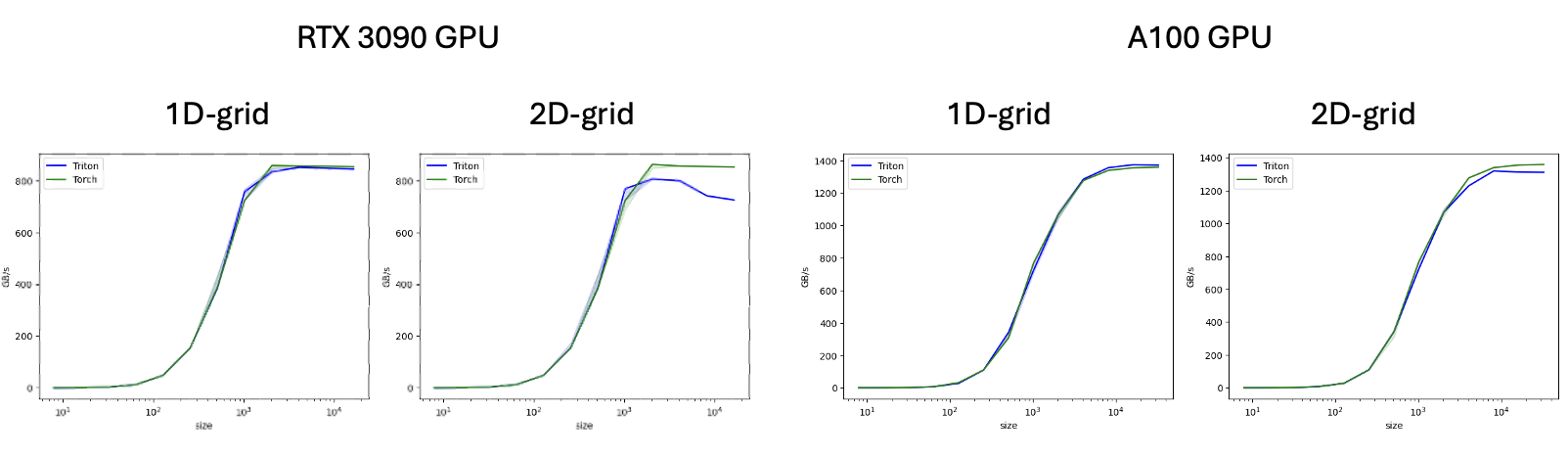
I felt there is quite a jump in technicality from tutorial 1 (vector addition) to tutorial 3 (matrix multiplication) on Triton’s website and I thought let me write a kernel that might fit more in-between in difficulty (for my learning and others) of writing a kernel to add two matrices. I also thought I’d run a little experiment to check how the performance compares when writing the kernel with a 1-dimensional versus a 2-dimensional grid. Below is the code for both kernels and you can find the full code on Google Colab:
import torch
import triton
import triton.language as tl
@triton.jit
def add_matrix_1dpid_kernel(x_ptr, y_ptr, output_ptr, H, W, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
row_id = pid // tl.cdiv(W, BLOCK_SIZE)
col_id = pid % tl.cdiv(W, BLOCK_SIZE)
row_ptrs = (row_id * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE))[:, None]
col_ptrs = (col_id * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE))[None, :]
ptrs = row_ptrs * W + col_ptrs
mask = (row_ptrs < H) & (col_ptrs < W)
x = tl.load(x_ptr + ptrs, mask)
y = tl.load(y_ptr + ptrs, mask)
output = x + y
tl.store(output_ptr + ptrs, output, mask=mask)
@triton.jit
def add_matrix_2dpid_kernel(x_ptr, y_ptr, output_ptr, H, W, BLOCK_SIZE: tl.constexpr):
row_id = tl.program_id(0)
col_id = tl.program_id(1)
row_ptrs = (row_id * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE))[:, None]
col_ptrs = (col_id * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE))[None, :]
ptrs = row_ptrs * W + col_ptrs
mask = (row_ptrs < H) & (col_ptrs < W)
x = tl.load(x_ptr + ptrs, mask)
y = tl.load(y_ptr + ptrs, mask)
output = x + y
tl.store(output_ptr + ptrs, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor, pid_dim=1, BLOCK_SIZE=32):
output = torch.empty_like(x)
H, W = output.shape[0], output.shape[1]
if pid_dim == 1:
grid = lambda meta: (triton.cdiv(H, meta['BLOCK_SIZE']) * triton.cdiv(W, meta['BLOCK_SIZE']), )
add_matrix_1dpid_kernel[grid](x, y, output, H, W, BLOCK_SIZE=BLOCK_SIZE)
else:
grid = lambda meta: (triton.cdiv(H, meta['BLOCK_SIZE']), triton.cdiv(W, meta['BLOCK_SIZE']))
add_matrix_2dpid_kernel[grid](x, y, output, H, W, BLOCK_SIZE=BLOCK_SIZE)
return output
After running the benchmarks I was surprised to see that without much optimization the kernel performed equally well to the default torch addition kernel! Intriguingly, the performance of the 1d-grid-kernel was better than the 2d-grid kernel on an RTX 3090 GPU, yet the performances were more similar on an A100 GPU. If there are any Triton wizards out there, please feel free to let me know why!